EL ADN TALLER 6
TALLER 6 FECHA 17 DE MAYO ENTREGA 31 DE MAYO
EL ADN ácido desoxirribonucleico
El ADN es «la molécula de la vida», y es la que lleva codificada la información genética característica de los diferentes seres vivos. Mediante ese código, regula el funcionamiento de cada tipo de célula; controla la transmisión de esa información, tanto en el tiempo como en el lugar de actuación de la misma; coordina la complejísima red de interacciones del funcionamiento celular y tisular; controla también su propia duplicación, reparación y autorregulación. Igualmente, controla y coordina los procesos de reproducción y mantenimiento de las características de cada especie. Todas estas actividades funcionales son reguladas y conducidas por un conjunto de instrucciones que constituyen el llamado código genético. El resultado se basa en un equilibrio entre la influencia del ambiente y esta compleja red funcional del ADN que muestra, además, un muy alto grado de plasticidad. Por ello, el genoma puede producir respuestas adecuadas a diferentes cambios del ambiente, manteniendo ese equilibrio. No obstante, a pesar de la importante capacidad homeostática del genoma, es susceptible de sufrir alteraciones por ciertos agentes que modifican el ambiente, dando lugar a efectos adversos y patológicos.
Hoy en día, la doble hélice del ADN es probablemente la más emblemática de todas las moléculas biológicas. Ha inspirado escaleras, decoraciones, puentes peatonales (como el de Singapur que se muestra a continuación) y más.
Tengo que estar de acuerdo con arquitectos y diseñadores: la doble hélice es una estructura hermosa, una cuya forma se acopla con su función de manera extraordinaria. Pero la doble hélice no siempre fue parte de nuestro léxico cultural. De hecho, hasta la década de 1950, la estructura del ADN seguía siendo un misterio.
Los componentes del ADN
La molécula de ADN está constituida por una doble cadena en la que cada una de sus hebras está formada por uniones covalentes sucesivas entre un azúcar (desoxirribosa) y una molécula de fosfato. Cada azúcar de las dos cadenas está unido a una de las siguientes 4 bases nitrogenadas adenina (A), guanina (G), citosina (C) y timina (T). Estas 4 bases tienen distintas posibilidades de unión entre ellas a través de puentes de hidrógeno. Así, la A y la T, tienen 2 puentes de hidrógeno, mientras que la G y la C, tienen 3 puentes de hidrógeno. El número de puentes de hidrógeno establece una complementariedad específica entre las bases que determina sus uniones. Sin embargo, en la molécula del ácido ribonucleico (ARN), la T es substituida por el uracilo (U).
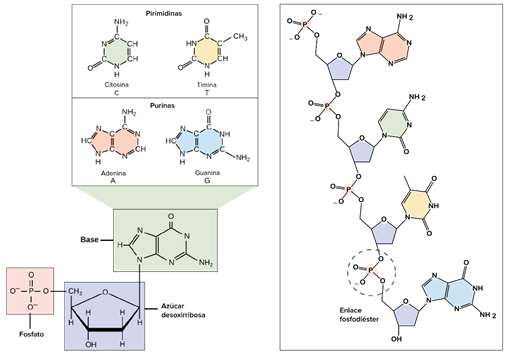
Crédito de las imágenes: panel izquierdo, imagen modificada de "Ácidos nucleicos: Figura 1", de OpenStax College, Biología (CC BY 3.0). Panel derecho, imagen modificada de "La estructura química del ADN," de Madeleine Price Ball (CC0/dominio público).
Los nucleótidos del ADN forman cadenas unidas por enlaces covalentes, los cuales se forman entre el azúcar desoxirribosa de un nucleótido y el grupo fosfato del siguiente. Este arreglo resulta en una cadena alternante de grupos desoxirribosa y fosfato en el polímero de ADN, estructura conocida como esqueleto azúcar fosfato
En el ADN, los dos extremos de los «esqueletos» de las dos cadenas complementarias de unidades «fosfato-desoxirribosa-base nitrogenada» (llamadas nucleótidos) terminan en un grupo fosfato en uno de los extremos que se denomina extremo y un hidroxilo del azúcar en el otro extremo, que se denomina 3’. Así, los dos «esqueletos» de desoxirribosa-fosfato-base se enfrentan en sentido contrario de manera que el extremo 5’ se enfrenta siempre al 3’ a través de las uniones complementarias de las bases, lo que confiere estabilidad a la doble cadena de ADN.
CODIGO GENETICO
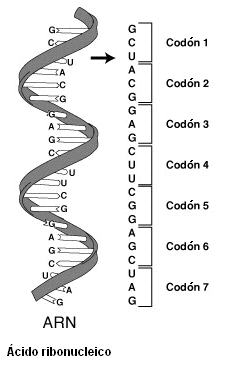
El ADN codifica la información genética mediante combinaciones de las bases, de forma que cada secuencia correlativa de 3 bases (triplete), que se denomina codón, codifica un aminoácido. Así, el codón ATG corresponde a la metionina (fig. 1b), y también es el que marca el sitio donde se inicia la lectura para el ARN mensajero (ARNm), que copiará el mensaje de los genes para trasladarlo al citoplasma, donde se formará la proteína que codifica cada gen. Hay también 3 grupos de tripletes (TAA, TGA, TAG) que constituyen codones de parada.
Como las bases son 4, se pueden producir 43=64 combinaciones diferentes. Sin embargo, como los aminoácidos son 20, el código genético es redundante porque varias combinaciones de tripletes codifican un mismo aminoácido. Por ejemplo, la metionina solo la produce un único triplete, mientras que la glicina es codificada por 4, y la arginina por 6 codones.
Función del código genético para la transcripción del mensaje
Cuando el ADN ha de trasladar el mensaje necesario para que en el citoplasma se forme una proteína, las 2 cadenas del ADN se separan en la zona que codifica el tipo y orden de los aminoácidos de esa proteína (el gen correspondiente). Ese mensaje va codificado en una de las dos cadenas, y ese mensaje se va a transcribir al ARNm, que lo trasladará al citoplasma para formar la proteína que codifica ese gen, la cadena que lleva el sentido de los aminoácidos de la proteína (cadena con sentido) no es la que se copia sino la otra (cadena con el sentido contrario o antisense), manteniéndose así el orden adecuado (el sentido) de los aminoácidos en el ARNm para formar la proteína. Por ejemplo, el código del segundo triplete del ADN de la cadena con sentido es el GGG (que corresponde al aminoácido glicina), sin embargo el ARNm, copiará el segundo triplete de la cadena sin sentido, que es CCC, y por tanto el ARNm llevará el código complementario GGG que codifica el aminoácido glicina, que es el que debe tener en segundo lugar la proteína que codifica ese gen. Por el contrario, si el ARNm copiara la cadena con sentido, nunca se mantendría el mensaje. En nuestro ejemplo, si el ARNm hubiera copiado el segundo triplete de la cadena con sentido, el codón del ARNm habría sido CCC (prolina), por lo que el segundo aminoácido de la proteína no habría sido la glicina, sino la prolina, que no mantendría el orden y tipo de aminoácidos del código del gen.
Un mismo gen puede dar lugar a diferentes proteínas mediante el proceso de transcripción alternativa (alternative splicing). Es decir, formando distintos ARNm por distintas combinaciones de unión de los exones en cuanto al número y exón.
Alteraciones del código genético por mutaciones
Como ya sabemos, combinaciones de 3 de las 4 bases A, G, T y C, codifican los distintos aminoácidos y, mediante diferentes combinaciones de aminoácidos de la cadena del ADN, se codifican las distintas proteínas. Cualquier cambio que se produzca en la combinación de las bases (o de los tripletes), puede modificar el código del ADN y alterar la expresión de la proteína. Por ejemplo, si en un triplete TCA, que codifica el aminoácido serina, se produce un cambio de la T por una C, el aminoácido que ahora codifica el triplete CCA es una prolina, que es muy diferente de la serina, por lo que se altera la proteína. Estas alteraciones se consideran mutaciones génicas. Sin embargo, no todas las mutaciones van a ser patológicas, ni van a tener el mismo efecto en la proteínas.
 Cualquier cambio que se produzca en la combinación de las bases (o de los tripletes), puede modificar el código del ADN y alterar la expresión de la proteína. Por ejemplo, si en un triplete TCA, que codifica el aminoácido serina, se produce un cambio de la T por una C, el aminoácido que ahora codifica el triplete CCA es una prolina, que es muy diferente de la serina, por lo que se altera la proteína. Estas alteraciones se consideran mutaciones génicas. Sin embargo, no todas las mutaciones van a ser patológicas, ni van a tener el mismo efecto en la proteína.
Cualquier cambio que se produzca en la combinación de las bases (o de los tripletes), puede modificar el código del ADN y alterar la expresión de la proteína. Por ejemplo, si en un triplete TCA, que codifica el aminoácido serina, se produce un cambio de la T por una C, el aminoácido que ahora codifica el triplete CCA es una prolina, que es muy diferente de la serina, por lo que se altera la proteína. Estas alteraciones se consideran mutaciones génicas. Sin embargo, no todas las mutaciones van a ser patológicas, ni van a tener el mismo efecto en la proteína.
Teniendo en cuenta cómo los distintos cambios (mutaciones) afectan a la función de la proteína, esas mutaciones las podemos separar en 2 grupos: a) las que no alteran la función, que pueden ser de 2 tipos: mutaciones silenciosas y mutaciones conservadoras. b) Las que alteran la función, que pueden ser de varios tipos: mutaciones no conservadoras, mutaciones sin sentido y las que se producen por cambios (ausencia o ganancia) de un número de bases que no sea múltiplo de 3.
Con objeto de entender mejor estos aspectos. En primer lugar el mensaje de un gen de ocho tripletes codifica una proteína de ocho aminoácidos, y el mensaje de esta proteína debe tener un sentido funcional. Ese mensaje, en nuestro ejemplo, daría lugar a una frase con ocho palabras de tres letras y con sentido, por ejemplo «los dos van sin más fin que ver». Sin embargo, si en el segundo triplete (TCA), que codifica la serina, se cambia la T por una A (ACA) el aminoácido resultante es la treonina, que es muy similar a la serina, por lo que no cambia la función, y se considera una mutación conservadora. En otras ocasiones, el cambio puede dar lugar al mismo aminoácido (por ejemplo TCA se cambia por TCC, que también codifica la serina), por lo que no cambia el sentido y se llama mutación silenciosa. Por el contrario, en el tercer triplete, el cambio de una T por una C, se traduce en el aminoácido prolina (CCA), que es muy diferente de la serina (TCA) por lo que altera la proteína (la frase ya no tiene sentido), siendo una mutación no conservadora.. Lo mismo ocurre si se produce ganancia de alguna base, o cualquier otro cambio de bases en números que no sean múltiplos de 3.
ACTIVIDAD
- Que es el ADN
- Que son los nucleótidos
- Menciona las bases nitrogenadas
- Dibuja una cadena de ADN donde se identifique los codones